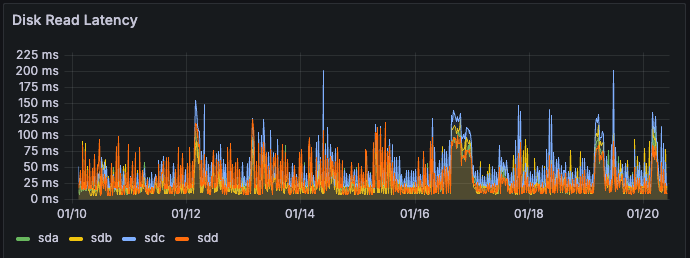
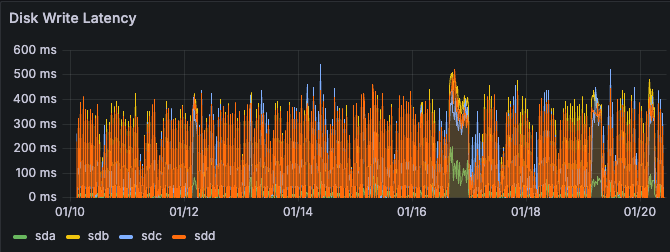
StorageGRID JMX becomes unavailable during heavy workloads
Applies to
NetApp StorageGRID
Issue
- Unable to communicate with node alert triggers due to an unresponsive JMX service on a Storage Node but it resolves itself in a few minutes
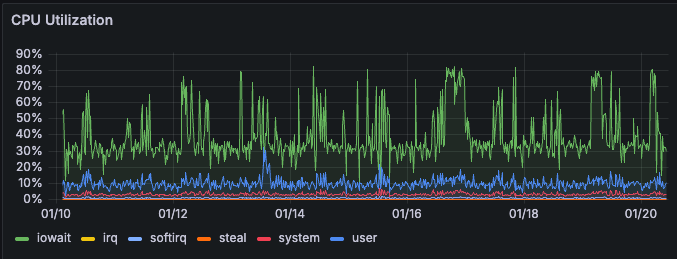
- A significant increase in the CPU Utilization
iowaitcan be seen in Grafana> Node (Internal use)
- Large spikes in Disk Read and Disk Write latency are found in Grafana > Node (Internal use) correlating with CPU spikes