Elastic Sizing with FlexGroup Volumes
Applies to
- ONTAP 9
- FlexGroup
Answer
What is elastic sizing?
Note: For more detailed information on elastic sizing see TR-4571.
This article describes what elastic sizing is and how it works with FlexGroup volumes, as well as what impact it can have on workloads.
Elastic sizing (introduced in ONTAP 9.6) is a way for ONTAP to better manage space allocation in a FlexGroup volume, with the goal of preventing "out of space" errors in constituent volumes from causing write failures to files. Elastic sizing is different from autogrow/autoshrink in that the goal is not to increase the overall capacity footprint of the volume. Instead, elastic sizing keeps the total volume size intact and will leverage free space across constituent volumes inside the FlexGroup to borrow/trade space to accommodate writes.
Elastic sizing is not intended to eliminate the need to manage capacity in the FlexGroup - steps should still be taken to ensure there is adequate free space in the volume and across constituents and should not be considered a replacement for space management.
FlexGroup volumes will still perform ingest load balance as usual, so imbalances across the volume should be addressed without need for manual intervention.
How it works
Elastic sizing will kick in only if a file write has reached a point where ONTAP is about to issue an "out of space" error to the client performing the write. Before that message gets sent, ONTAP will make a last-ditch effort to find some available space in the FlexGroup by borrowing 1% of the total capacity of a constituent volume in the FlexGroup - between 10MB and a default maximum of 10GB.

These values are adjustable via the node-level "flexgroup set' commands but should not be modified without guidance from engineering.
When a file write is about to fail, ONTAP scans the constituent volumes for available space and will reduce the size of one of those constituent volumes and add that amount of space to the constituent volume that is about to run out of space.
Impact of elastic sizing
This process is not free - performance will take a hit when this happens as the write pauses to find space. This will show up as latency spikes in the workload. The impact will vary based on the amount of space needed to complete the write, as well as the number of times ONTAP has to search for space. For example, since we only take 1% of space from a constituent volume at a time and the amount could be as low as 10MB, then a file that needs 1GB to finish a write will need to pause around ~100 times to give the proper amount of free space. Conversely, if 1% of the constituent volume is 10GB, then the write would only need to pause once to complete.
The following example shows a test where a file was copied to a FlexGroup. In the first test, the FlexGroup constituent wasn't large enough to hold the file, so elastic sizing was used. The 6.7GB file took around 2 minutes to copy:
[root@centos7 /]# time cp Windows.iso /elastic/real 1m52.950suser 0m0.028ssys 1m8.652s
When the FlexGroup constituent volume was large enough, the same copy took 15 seconds less:[root@centos7 /]# time cp Windows.iso /elastic/
real 1m37.233s
user 0m0.052s
sys 0m54.443s
That shows there can be a real latency impact when elastic sizing enacts.
The following graphs illustrate the latency hit on the constituent volume: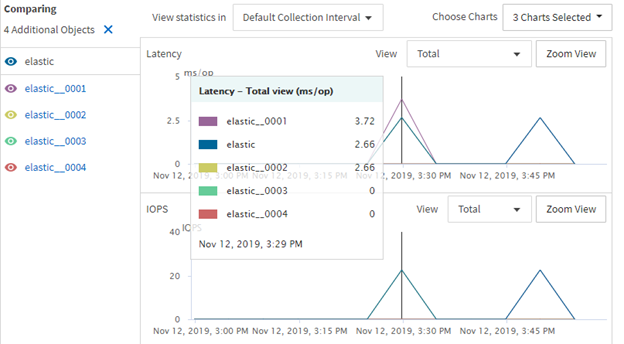
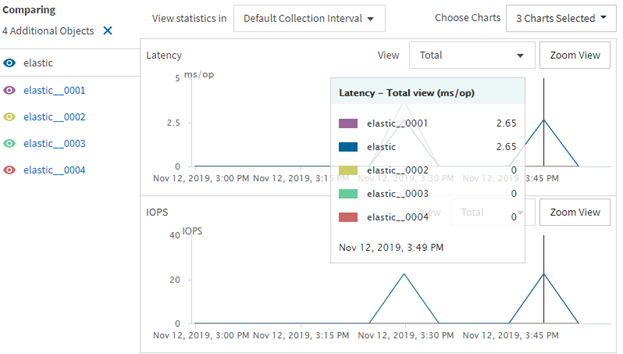
The constituent volume 0001 as about .5ms more latency when elastic sizing is being enacted:
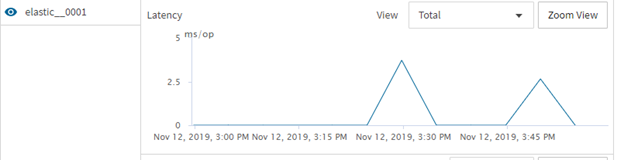
Remediating issues with elastic sizing
If elastic sizing is kicking in on a workload, that means the volume is no longer sized appropriately and remediate actions should be taken, regardless of if there is performance impact. Elastic sizing is simply an insurance policy against failed writes/corrupted files and should not be viewed as a panacea.
To prevent elastic sizing from kicking in:
- Review all constituent volume sizes in the environment for evenness of balance across constituent volumes. If one constituent has much more used space than others, then further investigation into why this is the case should be done (for example, was a bunch of data deleted? Did a file grow very large? Were a lot of files zipped into a single tar file?).
- If possible, delete some data to free up space, as well as snapshots that lock that data in place.
- Increase the size of the entire FlexGroup volume to increase the available free space.
- Look into the benefits of FabricPool tiering if using AFF; look into inactive data reporting to give a ballpark estimate of space savings across active file system and snapshots.
- Ensure all available storage efficiencies are enabled.
The goal is to free up enough space in each constituent volume so that a single file won't cause elastic sizing to borrow space from other constituent volumes. That threshold of free space will vary depending on average file size and largest file size in a workload, as well as if files in the volume grow over time.
Recommend setting alerts/warnings for "volume nearly full" and/or leveraging quotas to help monitor free space. TR-4571 covers how to use space monitoring with FlexGroup volumes.
Generally, it's best to notify when a constituent volume hits no more than 80% used to allow adequate time to plan and rectify capacity issues.
Other considerations
Normalization
After the FlexGroup capacity has adjusted (as in, files have been deleted or size has been added to the flexgroup), the constituent volume capacity will normalize and return back to their regular capacity levels on their own.
Autogrow
Volume autogrow can be used in conjunction with elastic sizing, but they operate independently. This means that if volume autosize is enabled on the volume, then elastic sizing will no longer be in use.
::*> vol show -vserver DEMO -volume elastic* -fields size,used,autosize-mode
vserver volume size used autosize-mode
------- ------------- ------- ------- -------------
DEMO elastic 15.73GB 6.78GB grow
DEMO elastic__0001 2.50GB 68.34MB grow
DEMO elastic__0002 2.50GB 67.44MB grow
DEMO elastic__0003 8.23GB 6.58GB grow
DEMO elastic__0004 2.50GB 69.25MB grow
5 entries were displayed.
::*> event log show -message-name *auto*
Time Node Severity Event
------------------- ---------------- ------------- ---------------------------
11/12/2019 16:55:59 ontap9-8040-01 NOTICE wafl.vol.autoSize.done: Volume autosize: Automatic grow of volume \'elastic__0003@vserver:7e3cc08e-d9b3-11e6-85e2-00a0986b1210\' by 118MB is complete.
Additional Information
additionalInformation_text